Muito se fala sobre o conceito do Delta Lake no ambiente Databricks, mas você sabe o que levou ao desenvolvimento desta tecnologia?
Comecemos com a definição do que seria o Delta Lake, disponível no Guia do Delta Lake e do Delta Engine:
“O Delta Lake é um projeto open-source que permite construir uma arquitetura LakeHouse em um ambiente Data Lake, permitindo transações ACID, a manipulação escalável de estrutura de tabelas e a unificação dos processos de carga batch e streaming. Tudo isso em ‘Data Lakes’ baseados em armazenamento S3, ADLS, GCS e HDFS. ”
Muito conceito junto, concorda? Não deu para entender ainda? Não se preocupe!
Para que fique mais claro, vamos retroceder no tempo. Precisamos entender de onde viemos e para onde vamos na evolução da análise de dados, e porque neste processo o Delta Lake ocupa um espaço importante em termos de inovação.
De onde viemos: A era dos Data Warehouse
A década de 80 e a primeira década do século XXI corresponde ao período de ascensão e predomínio do Data Warehousing (DW) que correspondem a sistemas usados para relatórios e análise de dados (para simplificar, adotaremos a sigla DW deste ponto em diante).
O DW se tornou um componente fundamental da inteligência de negócios (Business Intelligence — BI). Esta categoria corresponde a repositórios centrais de dados integrados, oriundos de diversos sistemas das empresas. Geralmente suportados por bancos de dados relacionais (RDBMS).
A análise de dados é possível através de relatórios desenvolvidos conforme a necessidade dos usuários. Eles são o ponto de partida no desenvolvimento, cuja peça chave neste processo seria o Analista de Negócios (ou Analista de BI)
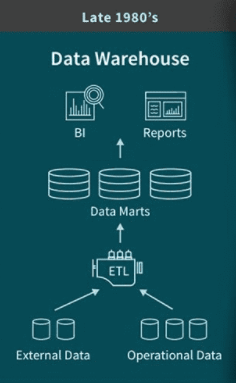
Fonte: Blog Databricks
Os dados que alimentam o DW se originam de sistemas internos, exigindo uma série de passos para sua extração, tratamento e carga no DW (uma técnica chamada de ETL/ELT — extract , transform, load). Após a carga, elas ficam disponíveis para relatórios desenvolvidos sob demanda.
Considerado o “estado da arte” do BI, e fundamentado em metodologias como os métodos Kimball e Inmon, o DW — no entanto — demanda um tempo significativo para sua construção.
Seu foco de análise são os dados passados, observando-se indicadores da empresa (KPIs) e traçando-se estratégias futuras. Esta abordagem apresenta suas limitações, correspondendo à imagem de “se dirigir um carro em uma estrada, baseando-se somente nas imagens do espelho retrovisor”.
Esta falta de flexibilidade, fortemente amarrada aos relatórios pré-definidos, se tornou latente com a chegada da “era digital”.
O advento da era digital: Surgem as limitações do DW
As características do DW (seu alto custo, sua estrutura rígida) tornaram sua aplicação mais limitada no início era digital, onde novos canais de informações foram incorporados aos negócios a partir de 2002 (vídeos, áudios, dados de sensores, comentários em redes sociais), gerando enormes volumes à uma taxa exponencial. As empresas compreenderam que estes dados poderiam esconder informações valiosas para elas. Mas havia um desafio: como incorporar estes dados em uma estrutura rígida e pouco flexível como o DW?
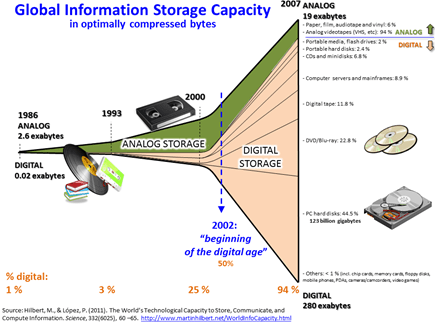
Fonte: Big Data em Wikipedia
Na época, as empresas se encontravam incapacitadas de processar estes dados, devido principalmente à ausência de uma tecnologia acessível.
Tal tecnologia exigiria uma estrutura mais flexível e menos amarrada às características dos bancos de dados do DW (dados rigidamente estruturados, controle transações, integridade dados, auditoria, etc.).
Estas características, apesar de importantes, precisavam ser “sacrificadas” para uma maior agilidade e flexibilidade no armazenamento e processamento do enorme volume de dados. Algumas informações apresentavam também um formato incompatível para o DW (texto livre/áudio/vídeo).
A futura tecnologia precisaria estar disponível para novas aplicações, como análise e ciência de dados (modelos de machine learning), para previsões e análise mais complexas que permitissem uma combinação e uso mais ágil dos dados, além da capacidade dos relatórios do DW.
O surgimento do Data Lake
As pesquisas em tecnologia levaram ao conceito do Big Data e às plataformas open-source como o Hadoop visando o armazenamento e processamento distribuído de um grande volume de dados. O Hadoop especialmente permitiu o surgimento do Data Lake partir de 2011.
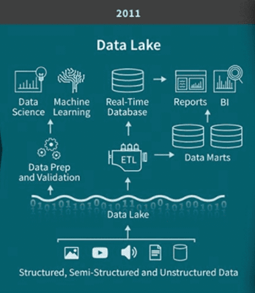
Fonte: Blog Databricks
O Data Lake trouxe uma série de vantagens. Segundo James Dixon (Pentaho), podemos pensar no Lake como
“ …um reservatório de água em estado natural, em oposição a prateleiras de garrafas d’água purificadas e prontas para consumo… ”
“ .. Onde é possível manipular a água do reservatório de formas diferentes que as dos processos únicos de purificação, engarrafamento e consumo …”
Fonte: Blog Solvimm
Entraram em cena novos profissionais, como o Analista de Dados e o Cientista de Dados. Através de modelos matemáticos, procurava-se obter “insights” para solução de problemas diversos.
O DW ainda continuava a ocupar um espaço dentro deste grande sistema, mas delegava seu protagonismo como fonte principal de análise de dados ao Data Lake.
O advento da nova plataforma — no entanto — parecia indicar que o conceito de DW estava ultrapassado e destinado à obsolescência … até que o mercado se deparou com alguns problemas que forçaram à uma reflexão sobre o Data Lake.
O surgimento do Lakehouse: Para onde vamos
O Data Lake foi construído com o conceito de “uma única gravação e várias leituras”, não estando preparado para atualizações de dados muito comuns no DW, como UPDATE, DELETE ou MERGE.
À medida que os dados sofriam alterações, tornava-se trabalhoso manter a integridade de informações no Data Lake, obrigando a fluxos de cargas envolvendo operações mais complexas, como reparação e/ou reconstrução de dados a cada nova carga.
O schema flexível do Lake (permitindo a alteração da estrutura das tabelas ou tipos de coluna), tornava os dados mais suscetíveis a “corrupção”. Seu processamento paralelo podia gerar conflito durante os processos de gravação. A falta de rastreabilidade das atualizações dificultava a governança de dados.
E estes problemas no passado haviam sido resolvidos pelos DW.
Haveria então uma forma de mesclar as melhores características do DW e do Data Lake, garantindo tanto sua confiabilidade, flexibilidade e rapidez?
Em janeiro de 2021, a universidade de Stanford, em conjunto com a Databricks, lançaram um artigo onde previam que a arquitetura do DW como a conhecemos definharia e seria substituída nos anos futuros por um novo padrão arquitetônico, o chamado LakeHouse.
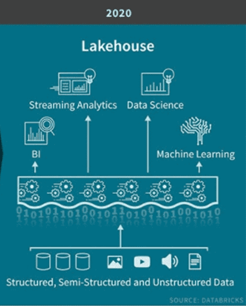
Fonte: Blog Databricks
Na opinião dos autores, os problemas dos Data Lakes atuais correspondiam a situações que haviam sido completamente resolvidas na época dos DW.
Estas capacidades “perdidas” poderiam ser novamente adotadas com o LakeHouse, apresentando características combinadas do Data Lake (formato de dados aberto, armazenamento e processamento paralelo) e do DW (controle transações, governança, qualidade dados).
Delta Lake: A peça fundamental do Lakehouse
Para que o conceito do LakeHouse se tornasse uma realidade e pudesse funcionar sobre a camada do Data Lake, a Databricks desenvolveu um projeto open-source de uma nova tecnologia à qual deu o nome de Delta Lake.
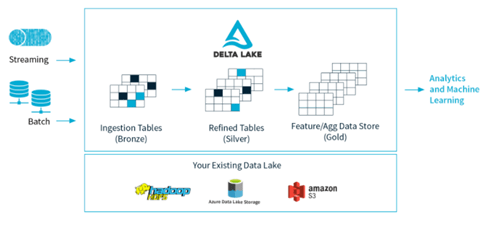
Fonte: Delta Lake
Basicamente o Delta Lake oferece uma série de recursos como:
· Controle de Transações: o modelo ACID do DW foi resgatado pelo Delta, garantindo que os usuários só consultam dados resultantes de transações finalizadas com sucesso. As pendentes são isoladas para evitar leituras incorretas. O Delta garante que transações concorrentes sejam executadas com o mínimo de conflitos;
· Processamento escalável do metadados: cada tabela delta está atrelada a um schema (a estrutura que relaciona as colunas e seus tipos). O schema é respeitado pelo Spark de forma transparente, independente do volume dados, tamanho tabelas, etc.;
· Versionamento de Dados: O Delta permite que sejam mantidas versões (fotos) dos dados após cada alteração efetuada, permitindo consultas históricas dos dados (“time travel”). Estes recursos já existiam em alguns bancos de dados de DWs, como Oracle.
· Formato Aberto de arquivos: Os dados na Delta são armazenados no formato Parquet do Apache (formato colunar), permitindo compressão de dados a amarração do schema lógico com os dados físicos armazenados;
· Aplicação de schema (metadados): O delta garante que a definição do metadado (schema) seja aplicada aos dados que estão sendo inseridos ou alterados nas tabelas neste formato, impedindo que a corrupção dos dados com formatos incorretos;
· Evolução de schema (metadados): Como as necessidades de dados mudam constantemente, o Delta permite que alterações de estrutura de tabelas seja automática e transparente, sem necessidade de manutenções complicadas, que envolvam scripts DDL;
· Auditoria: As tabelas Delta apresentam log de transações, que permitem consultar todos os detalhes das alterações. Trata-se de uma característica existente em alguns bancos usados pelos DW;
· Atualização ou remoção de registros: ao contrário das tabelas “normais” de um Lake, uma tabela Delta suporta transações de UPDATE, DELETE e MERGE, uma característica disponível nos bancos de DW;
· Processo único para execuções em Lote ou Stream: na época do Data Lake, os engenheiros precisavam construir uma complexa arquitetura “lambda”, com um pipeline orientado para processamento em lote (batch) e outro para streaming (fluxo continuo de dados). Com o delta, as tabelas são usadas de forma transparente em qualquer um dos modos, sendo a disponibilidade dos dados imediata;
· 100% compatível com o Apache Spark: os desenvolvedores podem usar o Delta Lake em seus processos de ingestão de dados em Spark (pipelines), com alteração mínima na codificação;
· Open-Source: A tecnologia é open-source, o que significa que ele não está amarrado à plataforma Databricks e pode ser aplicado em qualquer arquitetura Cloud que use o Spark Padrão, com sistemas de arquivos tais como HDFS, S3 ou Azure Blob.
Do ponto de vista da Engenharia de Dados, a adoção do Delta permite uma significativa abstração e “simplificação” do processo de ingestão de dados pelas equipes, aumentando sua produtividade e permitindo que esta foque em atividades de maior valor agregado: performance, novas ingestões ou engenharia de Machine Learning.
Complementando esta tecnologia, a Databricks também recomendava no artigo a criação de três regiões no Lake, para organizar a evolução dos dados dentro dele:
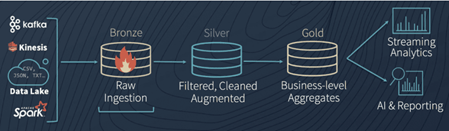
Fonte: Delta Lake
· Bronze: dados brutos, exatamente como eles foram gerados em suas origens. Aqui os tipos dos campos são definidos todos como string, para evitar filtragem dos dados;
· Silver: dados da Bronze que são lidos, filtrados, tratados e armazenados conforme seus data types corretos, estando prontos para uso;
· Gold: consolidações e agregações originadas de tabelas da camada Silver. Destinados para consumos pelas áreas (dashboards) ou para estudos de inteligência artificial;
Esta organização inclusive facilitaria a formação de um catálogo organizado dos metadados, um tema de extrema importância para a montagem de um Data Lake e para a implantação da Governança de Dados.
Quando devemos usar estas tecnologias?
Apesar deste artigo passar a impressão de uma “linha evolutiva”, com uma plataforma se sucedendo à outra, ainda é normal hoje em dia as empresas se valerem das três tecnologias.
Mas em quais situações posso optar por uma delas?
O quadro abaixo tem o objetivo de passar alguns esclarecimentos:
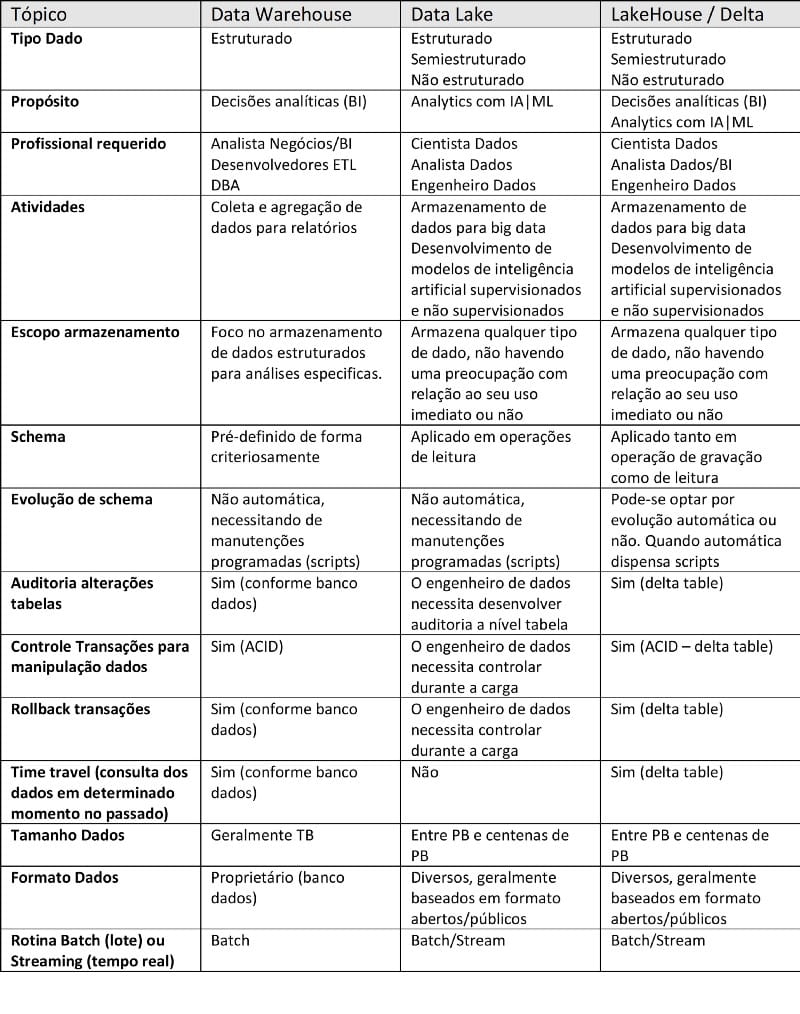
Fontes: Smart Data Collective e Dremio
Próximos passos: Onde obtenho mais informações?
Para mais informações sobre o impacto do Delta Lake e do LakeHouse nas empresas, sugerimos a consulta adicional destas fontes:
- everisTalks Webinar: Você conhece a arquitetura LakeHouse?
- Lab everis: Demonstração de aplicação na camada Bronze utilizando o Delta
Nenhuma das plataformas mencionadas aqui será uma solução viável sem uma boa governança de dados. Sobre o tema, recomendamos a leitura do artigo:
Medium NTT Data Brasil: Uma nova abordagem para a Governança de Dados
